One thing I am seeing over the years is that Git has become too commonplace - too ubiquituous so that people don't care how it actually works or why it works that way. It's just this magical thing that keeps your sourcecode safe - and as long as push and pull work they just don't care why or how it works.
Until git pull messes up your history, or you accidentally merged into the wrong branch or just a case of something went wrong™ and then they hope their Git client can bail them out.
So here is a very short guide on why Git is the way it is and why you should not be afraid of anything when it comes to working with git.
First thing to understand is that Git stores all of your committed files in a blob storage living inside your .git folder. Each and every file you ever committed got slashed into tiny files and placed in the .git folder. This is important because Git does not think in deltas or changes like other SCM systems but it thinks in snapshots. Each commit you do will commit the whole file to the blob storage. To save space git will internally map your files to multiple smaller files and have a blob object reference these smaller chunks (everything is addressed as a hash in git). So whenever you change something in that file git will not save the whole file a second time, but rather create a new blob object that references all the old chunks, alongside the new one you just changed.
Now that we know that Git has a storage that can return you every file ever committed in your repository we can talk about the commit and the tree. Files in itself are not very useful as we usually have a lot of these in our repository, so there is a object above the blobs that describes which versions of each blob belong together into a directory tree. Aptly named tree this is just a file that is more or less a mapping from the filename to the underlying blob hash. This is also important because if we change a file in a huge directory tree, a new version of that tree will just change one of these references to a new blob object (leaving all the other ones pointing to the old objects) - and that blob object will possible reference older chunks alongside the few changes we did in that file.
Why is this important? This also explains why git is so lightning fast. For every checkout operation git has to just look at the tree object, go into it's blob storage and store each file at the name it was referenced in the tree. Unlike other delta based SCMs where you had to get the last snapshot and then replay all changes since that snapshot to get to the current version. For git this is a constant operation that always takes the same amount of time - no matter which commit you check out.
The last concept to understand with git is the commit. A commit is basically a very small file that contains a few important pieces of information. It contains the SHA1 hash of the tree it is representing, the name of the author, the committer and the commit message. The git commit hash is exactly what the name implies: A shas1sum over this commit file. Thus a commit hash uniquely represents a commit, which unambiguously and cryptographically securely references a tree which represents (using the same sha1 concept) all files. If I tell you to check out version **d0ce065** of the project there is no doubt about what you are getting. Either your commit sha1 matches it's commit files contents or not. There is no way to corrupt that unit of your source code. Everything attached to a commit is securely identified by that one commit (since blobs, trees and chunks are all also in turn identified by their SHA1 sums).
So we end with a diagram like this (graphic by Scott Shacon):
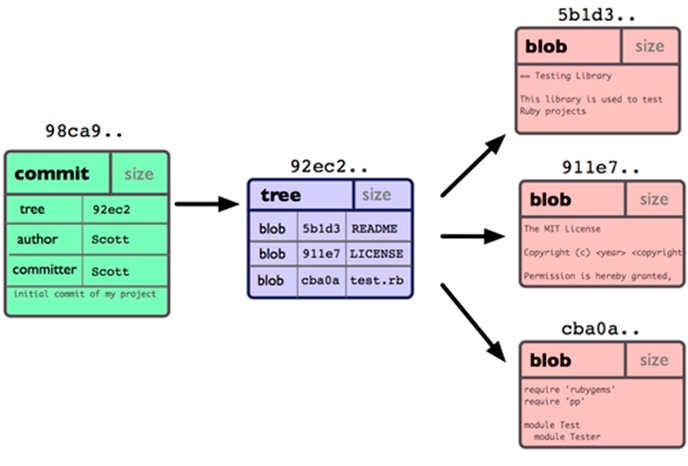
What is missing from this picture is the history. Where are the other commits? This is no SCM yet.
Well I left out one very important detail in my previous description. The commit file also contains the sha1 of it's parent commit. So if you remember that everything about a git commit is a sha1 hash, one commit also cryptographically secures the whole git history before it and makes it impossible to miss a commit or add ones without all hashes upstream to change.
Again this is best described with a diagram:
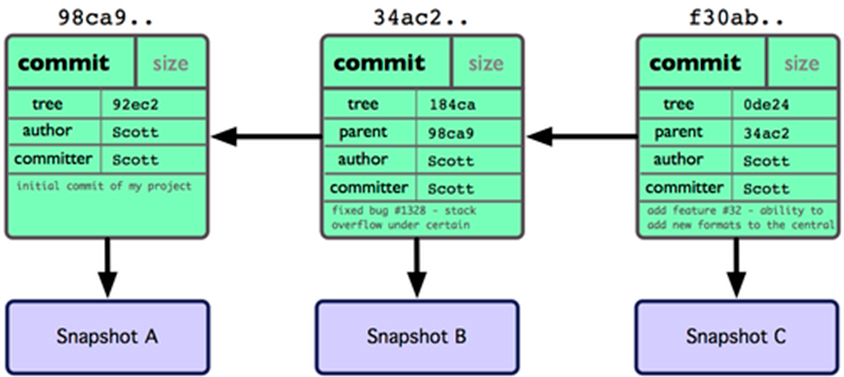
So this now also explains why in every git presentation ever there where arrows between the commits that always went backwards. Git is a acyclic directed graph. This also means that git commits only know about their parents - never about their children. So if you did something you are not proud of, just check out the parent commit and continue working there - your child commit will linger on in the git object storage for some time, but eventually git will forget about it and it's gone.
No branches?
If you think about all of the above for a second you will realize branches are there just for human comprehension. They are not needed in git. Everything git needs to know or reason about (and you) is stored in single commit sha1 hashes. The git datastructure has no concept what master or develop means, it can only reason about 9b09404973ca743d0f5e11367034250dff219637.
Branches are just cosmetic to make us stupid humans not have to remember sha1sums when we work with git. A branch is nothing more than a file that lives inside .git/refs/heads that contains exactly the shasum of the commit your branch is currently pointing to. Branches are pointers - they serve no (real) purpose and can be deleted at no cost without anything happening to the commit tree. Try this:
$ git clone https://github.com/dotless/dotless.git $ cd dotless/.git/refs/heads/ $ cat master => 9b09404973ca743d0f5e11367034250dff219637 <= This is the commit sha1.
Go ahead and do a git checkout 9b09404973ca743d0f5e11367034250dff219637 and you will get exactly the same working directory as if you had done git checkout master. This is so important because most of the time when stuff goes wrong with git people don't realize that having a commit on a branch where it does not belong is no big deal - just delete the branch and re-create it at the point where it actually should be.
Coincidentally remote branches are also just the same thing: pointers. Locally you can merge with your origin/master exactly because when you do a git pull or git fetch git updates the files inside .git/remotes/origin to the sha1sums that are on the server. These things are just local operations since all changes of the server are already living inside your .git directory.
So if you ever accidentally deleted a branch and forgot the commit sha1 it was at - that branch is not lost. It's still right there in your .git folder - you just have no clue how to ask git for it. That's the point where you can just run git reflog and you will see all the recent pointer/branch changes you did recently along with their sha1 sum for you to check out and recover.
$ git reflog
858b6db HEAD@{0}: merge laedit/Adding-support-for-'unit'-function: Merge made by recursive.
715db85 HEAD@{1}: checkout: moving from laedit-Adding-support-for-unit-function to master
715db85 HEAD@{2}: checkout: moving from master to laedit-Adding-support-for-unit-function
715db85 HEAD@{3}: merge nevett: Fast-forward
2a933ed HEAD@{4}: checkout: moving from nevett to master
715db85 HEAD@{5}: pull https://github.com/Nevett/dotless.git fix-mixin-important-recursive: Fast-forward
2a933ed HEAD@{6}: checkout: moving from master to nevett
2a933ed HEAD@{7}: checkout: moving from d1d2a822561fcd2c52a54b6bb8799000e4efecf9 to master
d1d2a82 HEAD@{8}: checkout: moving from MarkOSIndustries-master to d1d2a822561fcd2c52a54b6bb8799000e4efecf9
As you can see, each operation I did (even when I did not commit anything) is noted here and I can find the missing sha1sum to recover.